機械学習 *1 の手法を使ってPostgreSQL のモニタリングとパフォーマンス向上を目指す目的で開発していた
pg_plan_inspector というフレームワーク を公開した。
とりあえず動画 を。
この動画は、クエリの進捗を推測して表示するモジュールのデモ動画である。
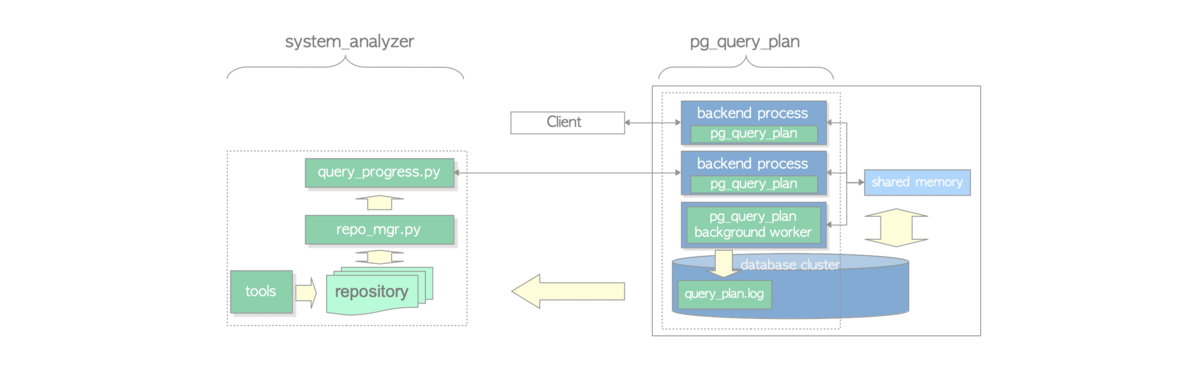
アーキテクチャ
詳細はREADME を参照。
開発動機
このフレームワーク の開発動機は以下の2つ:
(純粋な外部モジュールだけで、つまりPostgreSQL 本体を改造することなく)リアルタイムでクエリの実行状況をモニタリングする。
常に捨てられているクエリの実行計画を使って、クエリプランの改善を行う。
現在のステータス
このフレームワーク はまだ開発が始まったばかりで、POC(Proof Of Concept)モデルである。
現時点で開発動機の1.については達成できた。
開発動機の2.については、簡単なツールでテーブルの属性間の関数依存性を抽出し、拡張統計(Extended Statistics)を設定すべき候補をリストアップすることができることを示した。詳細はREADME-tools 参照。
今後について
今後について、現時点では2段階の開発プランを持っている。
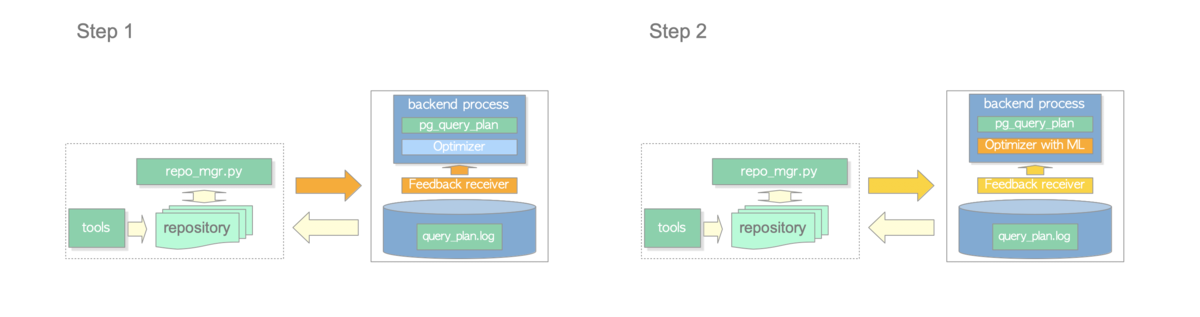
Step 1
現時点でクエリの進捗を推測するために、線形回帰モデルでOptimizerの推定したPlan Rowsを補正している。
逆の見方をすれば、Optimizerが推定する際に補正してもよいはずである。
実際、同様のアイディアは(アプローチや実装方法は異なるが)pg_plan_advsr が既に実現している。
よってStep 1では、回帰モデルで得たパラメータをPostgreSQL 側に渡し、Optimizerの推定値を補正する機能を実現する。
それから、今はアドホック な手法で関数依存性を抽出しているが、そのアルゴリズム も改良する予定。
Step 2
これまでの実装の過程で、線形回帰モデルによる補正はNested Loopには比較的有効であることがわかったが、
Hash JoinやMerge Joinでは補正が難しい場合が多いこともわかっている。
また、テーブルの属性間に関数依存性があるとPostgreSQL のoptimizerは不正確なPlan Rowsを推定してしまい、線形回帰モデルでは補正できない状況になることも多い。
これらの問題に、近年ではAI(もしくは広く機械学習 )の手法を使ってアプローチする論文やプロトタイプが数多く発表されている。
詳細はリファレンス の[6]や[7]などを参照のこと。
リファレンスに示したシステムのうち、いくつかはgithub でソースコード が公開されているので、使えるものは取り込んでしまおうと思っている。
またこれらは研究が目的であるため、純粋に正確なCardinality Estimationを得るアルゴリズム の開発を主眼としているようだが、
こちらは開発者なのでうまく動けばどのアルゴリズム でもよいし、実行後の結果を(教師データとして)フィードバックして学習をブーストすることも可能ではないかと目論んでいる。ま、この辺りは確証もない単なる思いつきである。
今後の計画